- 44 Posts
- 38 Comments
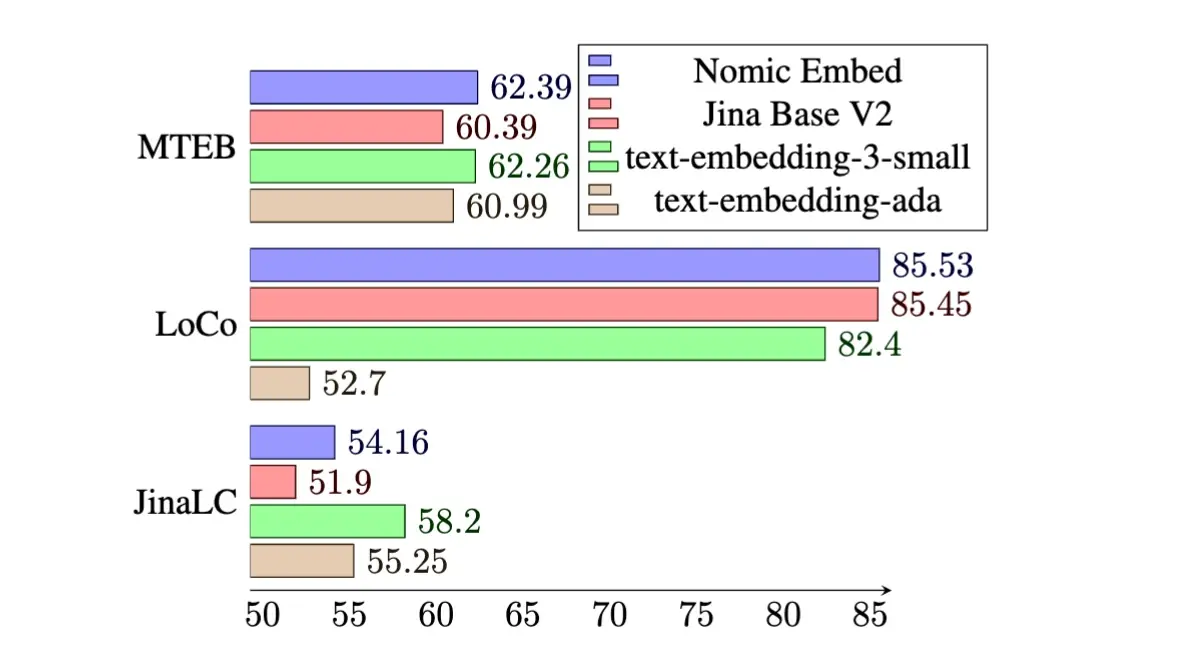




 1·11 months ago
1·11 months agoI use text-generation-webui mostly. If you’re only using GGUF files (llama.cpp), koboldcpp is a really good option
A lot of it is the automatic prompt formatting, there’s probably like 5-10 specific formats that are used, and using the right one for your model is very important to achieve optimal output. TheBloke usually lists the prompt format in his model card which is handy
Rope and yarn refer to extending the default context of a model through hacky (but functional) methods and probably deserve their own write up
Yeah so those are mixed, definitely not putting each individual weight to 2 bits because as you said that’s very small, i don’t even think it averages out to 2 bits but more like 2.56
You can read some details here on bits per weight: https://huggingface.co/TheBloke/LLaMa-30B-GGML/blob/8c7fb5fb46c53d98ee377f841419f1033a32301d/README.md#explanation-of-the-new-k-quant-methods
Unfortunately this is not the whole story either, as they get further combined with other bits per weight, like q2_k is Q4_K for some of the weights and Q2_K for others, resulting in more like 2.8 bits per weight
Generally speaking you’ll want to use Q4_K_M unless going smaller really benefits you (like you can fit the full thing on GPU)
Also, the bigger the model you have (70B vs 7B) the lower you can go on quantization bits before it degrades to complete garbage
If you’re using llama.cpp chances are you’re already using a quantized model, if not then yes you should be. Unfortunately without crazy fast ram you’re basically limited to 7B models if you want any amount of speed (5-10 tokens/s)




Yeah definitely need to still understand the open source limits, they’re getting pretty dam good at generating code but their comprehension isn’t quite there, I think the ideal is eventually having 2 models, one that determines the problem and what the solution would be, and another that generates the code, so that things like “fix this bug” or more vague questions like “how do I start writing this app” would be more successful
I’ve had decent results with continue, it’s similar to copilot and actually works decently with local models lately:
Yes agreed on the llama-2 models, they show a LOT of promise in the right tasks but they need some work to get back to what we remember from peak llama-1, i’m very excited for when that arrives in a week or two!
Yeah by all means! At this time I’d say text-generation-webui is my most mature and functional image, with koboldcpp being a close second but I just don’t work as closely with it
lollms-webui is a very interesting upcoming platform but it’s a solo dev so it’s a lot of work, my docker image works as long as you don’t need any personalities, but i’m working on that to see if I can get it sorted out :) for now though it’s definitely worth considering it beta or maybe even alpha
Would love to keep our communities tightly knit, FOS AI and localllama both have similar ideals coming from two different angles, so keep in touch :D
Hey thanks for the detailed writeup, this is great! Probably worth including a couple of the llama 1 models just because they’re more mature and ready to be used even tho licensing is awkward
Also if you’d like I maintain a few docker images for a couple tools (namely oobabooga, koboldcpp, and lollms-webui) that might be good for beginners to get their feet wet, can find them pinned at https://github.com/noneabove1182
 1·1 year ago
1·1 year agoBtw, any idea of recommended RSS feeds? Haha
Yup I’m interested in this! Thanks I’ll give it a download :)
Ah yes this is one I saw somewhere too that looked interesting but couldn’t find it again, I’ll give it another look!
 2·1 year ago
2·1 year agoI hate the formatting of this vs say guidance, but need to check its performance, at least it offers built in llamacpp support…

She really is, so fortunate to have her :)

 6·1 year ago
6·1 year agoHonestly an interesting thought and worth keeping in mind, I would love to see a lot more examples and more timing, especially for the pythonic ones, are they more efficient or just more python like?
For me it’s best for the apps where people don’t upload to Fdroid but I trust them
What’s your concern exactly? That they’ll install malicious apps on your phone?
Literally just installed this and set up with all my Foss apps, couldn’t be happier, works surprisingly well for “beta” haha
{kind=link}
That’s a good point I hadn’t considered and definitely puts it in perspective
This mildly surprised me, doesn’t seem explicit enough, a thumbs up can represent having received but not necessarily agreed, strange new world
For me I have to run down at a measly 13B, so I’ve been using mainly wizard and airoboros, hoping though that the new orca (or dolphin) models will work well, especially down to 7B, want to create a highly specialized home AI and would be so handy if I could QLora a really powerful but small model
You shouldn’t need nvlink, I’m wondering if it’s something to do with AWQ since I know that exllamav2 and llama.cpp both support splitting in oobabooga