
Not my blog, but the author’s experience reminded me of my own frustrations with Microsoft GitHub.
There are quite a few things I don’t like about GitHub, but calling it legacy makes no sense.
I’ve got to say, seeing this:
https://github.com/zed-industries/zed/network
instead of something like this:
https://fork.dev/blog/posts/collapsible-graph/
or this:
https://miro.medium.com/v2/resize:fit:4800/format:webp/0*60NIVdYj2f5vETt2.png
feels pretty damn legacy to me.
both of those aren’t websites. I use fork though and had no clue you could do that. I’ve needed that like 10 times in the last week alone haha
I am about to make you very happy.
alias gl='git log --graph --abbrev-commit --no-decorate --date=format:'\''%Y-%m-%d %H:%M:%S'\'' --format=format:'\''%C(8)%>|(16)%h %C(7)%ad %C(8)%<(16,trunc)%an %C(auto)%d %>|(1)%s'\'' --all'I use
git log --graph --all --remotes --onelinewhenever I need to shell into another computer, but it’s still too barebones for regular use.For my fellow fish shell users:
git log --graph --abbrev-commit --no-decorate --date=format:'%Y-%m-%d %H:%M:%S' --format=format:'%C(8)%>|(16)%h %C(7)%ad %C(8)%<(16,trunc)%an %C(auto)%d %>|(1)%s' --all
I was thinking “oh, network view, this is gonna be a good example”, but that comparison isn’t.
What specifically do you think is legacy in that comparison? The coloring? The horizontal layout? The whitespace?
The network view lays out forks and their branches, not only [local]/[local+1-remote] branches.
I don’t know what IDE that miro screenshot is from. But I see it as wasteful and confusing. The author initials are useless and wasteful, picking away focus. The branch labels are far off from the branch heads. The coloring seems confusing.
 bg looks like the same
bg looks like the sameWhat specifically do you think is legacy in that comparison? The coloring? The horizontal layout? The whitespace?
Note: I’ve changed the first link from https://github.com/cxli233/FriendsDontLetFriends/network to https://github.com/zed-industries/zed/network. Still the same view, but just a different repo to highlight the problems
- It’s in a small non-responsive box
- Ridiculous spacing
- If you want to see the commit messages, you either need to hover over a dot which increases visual scanning durations or you need to go to the commits view which only shows the commits on a single branch
- It doesn’t show commit messages
- It’s scrolling horizontally
- Branches cannot be collapsed
- Branches cannot be hidden/ignored
- No way to search for commits
- No way to select multiple commits
- Which also means no way to diff any specific commits together
- And there’s also no way to perform an action over a range of commits
- And there’s also no way to start a merge/merge-request/pull-request/etc… between two commits
- No way to sort by date/topologically
- Keyboard controls only moves view instead of selecting commits
I’ll stop here at 10 reasons (or more if you count the dot points), otherwise I’ll be here all day.
The network view lays out forks and their branches, not only [local]/[local+1-remote] branches.
Yes, but the others can do that while still being usable.
I don’t know what IDE that miro screenshot is from. […]
It’s gitkraken
[…] But I see it as wasteful and confusing. The author initials are useless and wasteful, picking away focus. The branch labels are far off from the branch heads. […]
The picture doesn’t do it justice, it’s not a picture, it’s an interactive view.
You can resize things, show/hide columns, filter values in columns to only show commits with certain info (e.g. Ignore all dependabot commits), etc… Here’s an example video.
[…]The coloring seems confusing.
You can customise all that if you want.
Do either of those tools show logs across forks though? The first link is a totally different purpose than the second two.
The first link is a totally different purpose than the second two.
The first link is going to there because that’s the only graph view that github has.
deleted by creator
I kinda got bored halfway through. From what I gather they’re salty that GitHub is switching to react? If that’s the issue then the headline is rather misleading isn’t it?
Surely legacy software is one that drifts into obscurity through lack of investment which is the polar opposite of GitHub rewriting their entire front end…
they’re salty that GitHub is switching to react
there’s your tl;dr
Nah. They’re salty that only the visible sourcecode is searchable. Which is a bug, imo.
From what I gather they’re salty that GitHub is switching to react?
No, that is not the point at all. React is just an incidental detail she considered while trying to figure out what was going on.
It’s not an incidental detail when the text is almost entirely around the issue caused by this (mis-)use of react. The author doesn’t give another argument to support their view.
There seems to be a rando paragraph about AI as well,then it trails off that they’re looking for recommendations for git blame clients. I couldn’t really figure out how it was all GitHub’s fault or where the word legacy fits in.
The thing is a new feature - AI-related in this case - contradicts the idea of legacy software to me, so I really don’t know what was the point of that other than “complaining about github”.
OP also felt the need to refer to the platform as Microsoft GitHub. So it seems likely this is all just grumbling about evil corp making changes
There’s a difference between the author being mad that github is switching to react and the author being mad that github is misusing react. It is possible to use react without breaking browsers find in page functionality, which is ultimately what the author is frustrated about.
Exactly. The complaint is that a basic feature no longer works as expected.
Crappy old websites that don’t behave properly with my browsers search function sound like legacy though. I agree the headline is worded a little strangely but I can see their point.
But their issue isn’t the old website. They’re complaining about the new version?
Yes, but they said it reminds them of crappy old ones.
That’s another issue though. Will it get better or more bloaty webapp, like modern reddit vs. old.reddit?
My one complaint: Search code in a repo, and then there is no link to return to the repo home. Back, back, back, back…
I got caught by this one today. I use the search feature all the time, and I don’t know why I didn’t notice that until today. I found the thing I was looking for, then wanted to go back to issues backlog for that repo, I clicked “Issues”, that just took me to a filtered view of my search term within issues. Deleting my search term didn’t help. I was clicking around for at least a minute before I realised there’s actually no way back to the main repo from that page.
The only issue they mention is browser page text search not working on rendered file view (blame).
The feels legacy conclusion doesn’t make any sense to me.
GitHub is not the only platform implementing virtual scrolling, partial rendering of rendered files. There’s a reason they do that: Files can get big, and adding various code highlighting and interactivity costs performance. It’s not a local code representation and rendered canvas. It’s rendered into a DOM and DOM representation, with markup and attached logic. Which at some point quickly becomes very inefficient or costly.
Not being able to use the browser text search is an unfortunate side effect.
I consider it a worsening modernization/feature addition. That’s the opposite of legacy. We’re moving forward (in a bad way), not stagnating.
When I click Blame, and then press Ctrl+F, it opens not my browser text search but the in-page in-file search. It works for me. (Not that I always use that search or like it.)
It would certainly help if the GitHub code search wasn’t utter garbage.
There’s a reason they do that: Files can get big
Oh, boy. Wouldn’t it be great if servers had a way to discover the size of the files on their storage without having to read them?
adding various code highlighting and interactivity costs performance
Somebody, quick, there’s work to be done on language theory so that we learn how to do those things with a cost just proportional to the file size!
(No way! Who is that Chomsky guy you keep telling me about?)
Dude, his point is that if you did not implement partial rendering on a big file, the browser will have to work extra hard to render that shit. Not to mention if you add any interactivity on the client side like variable highlighting that needs to be context aware for each language… that basically turns your browser into VSCode, at that point just launch the browser based vscode using the
.shortcut.It’s not a matter of the server side of things but rather on the client side of things.
Don’t really get your point here.
They virtualize the file because it’s big. They know the size.
It does indeed scale with the size of the file. That’s exactly the problem.
While I agree with the body of the post, the title is just utter bullshit in this context.
With that being said, GitHub is a prime example of Rails in action, warts and all. To many that use Rails it probably is erring towards legacy given some of the technical decisions made regarding frontend within Rails. Rails is one of those rare stacks where it isn’t uncommon to see the likes of jQuery powering parts of UI, and parts of the Rails stack trying to make quasi-SPA’s. Personal thoughts aside as a former Rails developer, it’s long been said that GitHub and Rails have probably been too heavily intertwined.
I can understand why they’re moving to React, but the gripe seems mostly with server-side rendering - which you can do within Rails. This just feels more like a feedback piece for a specific area of functionality over saying that GitHub is legacy.
I threw various keywords from that line into the browser’s command+F search box, and nothing came up.
When one clicks command+F while on the git blame, GitHub throws up their own search box. Not rendering everything at once is something a lot of stuff does.
Honestly, the ability to override menu keys is really a long-running flaw in browser UI, IMHO.
Firefox acquired a not-so-obvious way to disable that for a given site:
Click the “lock icon” to the left of the URL in the URL bar. Click “connection secure”. Click “more information”. In the window that comes up, click the “permissions” tab. On that page, there’s an option to “override keyboard shortcuts”. You can click “Block”, and it’ll prevent that particular website from overriding your keybindings.
This had been a long-running pet peeve until I ran into someone explaining how to disable it. I still bet that a ton of people who can’t find the option put up with that. Like, lemmy Web UI keyboard shortcuts clash with GTK emacs-lite keybindings, drives me nuts. Hitting “Control-E” to go to the end of the line instead inserts some Markdown stuff by default.
fwiw in the case of Ctrl+F, you can usually press it twice in a row to invoke the browser’s search instead. Discourse forums are common use cases.
Firefox acquired a not-so-obvious way to disable that for a given site
Thank you for sharing that! It drives me up a wall when I tap a standard browser shortcut only to have a web site intercept it and make something else happen instead.
the ability to override menu keys is really a long-running flaw in browser UI
They have a reason to do so here though. OP evaded their search box and couldn’t find the content. Because it’s not fully rendered. Because code files can get big, and rendering them to DOM with inline highlighting and hover actions, sidebar with infos, and interactivity becomes a performance problem. So they implement partial rendering / virtual scrolling.
So, I’ve got no problem with having page-specific functionality and allocating some kind of space of keybindings to them, right? Like, okay. Say that browsers reserved the Control-Alt prefix for webpages, and then had a list of functions that webpages could implement, and when they do, adding a visible button in a toolbar and having a hover tip to find those. That visible toolbar would solve any issue of discoverability of such functionality on a webpage (and by implementing that in the browser, the browser could choose to have a more-minimal form, like just an indicator that a page supports keybindings.) So the webpage doesn’t have to grab the browser’s keybindings. Or maybe we introduce a “browser button” or something, the way Microsoft did the Windows key.
But what I don’t like is having access to native functionality blocked by webpages. I don’t think that they should have overlapping keybinding space.
Emacs has a shitton of keybindings, users who heavily configure it, and a ton of add-on software that needs keybindings. What they did was to reserve some keybinding space for the editor, some for major modes, some for minor modes, and some for user-specified keybindings. These all don’t collide, so that the user doesn’t get functionality blocked by another piece of software:
https://www.gnu.org/software/emacs/manual/html_node/elisp/Key-Binding-Conventions.html
Don’t define
C-cletter as a key in Lisp programs. Sequences consisting ofC-cand a letter (either upper or lower case; ASCII or non-ASCII) are reserved for users; they are the only sequences reserved for users, so do not block them.Changing all the Emacs major modes to respect this convention was a lot of work; abandoning this convention would make that work go to waste, and inconvenience users. Please comply with it.
- Function keys
F5throughF9without modifier keys are also reserved for users to define. - Sequences consisting of
C-cfollowed by a control character or a digit are reserved for major modes. - Sequences consisting of
C-cfollowed by{,},<,,:or;are also reserved for major modes. - Sequences consisting of
C-cfollowed by any other ASCII punctuation or symbol character are allocated for minor modes. Using them in a major mode is not absolutely prohibited, but if you do that, the major mode binding may be shadowed from time to time by minor modes.
I get that websites need to have keybinding space, and have a legit reason to do so. But I don’t think that they should share keybinding space with the browser’s native functionality. If we want to have a “search” shortcut, hey, that’s cool. But lets leave the browser-native functionality available.
In Firefox, I have:
-
Alt-f for find. By default, this is Control-f, but normally both Control- and Alt- are reserved for the browser, and I’ve swapped the Control and Alt prefixes so that the menu keys don’t crash into the GTK emacs-lite keybindings. Some websites override this, which is really annoying if I’m trying to navigate around using conventional search; in emacs, it’s common for users to use search constantly to navigate around in a document.
-
Slash. This opens a mini-find, because I’m using vimium, but only if I don’t have a text-editing widget active, in which case the OS’s text editor gets it.
So I’ve got two different search keybindings and both are inaccessible at various points, because other software packages want to use keybinding space and there’s no convention for avoiding collisions.
My preference would be that there should be keybinding space for Firefox itself, keybinding space for the OS to use in things like text widgets, keybinding space for the OS (Microsoft dealt with this by adding and reserving the Windows key and mostly using that, except for traditional pre-existing conventions like Alt-F4 or Alt-Enter), keybinding space for OS add-ons, binding space for Firefox add-ons, and keybinding space for websites, and that these shouldn’t overlap (and insofar as possible, and I realize that this isn’t always possible for non-modified keybindings, to not change based on modality, like “this functionality isn’t available if you have a text widget active”).
- Function keys
Neat! Does that also block right-click capture?
In Firefox, you can also override right-click capture by holding shift while right-clicking.
I don’t know; I’d guess not, but haven’t tried to find out.
The other day though, I tried to use the blame view on a large file and ran into an issue I don’t remember seeing before: I just couldn’t find the line of code I was searching for. I threw various keywords from that line into the browser’s command+F search box, and nothing came up. I was stumped until a moment later, while I was idly scrolling the page while doing the search again, and it finally found the line I was looking for. I realized what must have happened.
Oh, I think I hit that too. Obnoxious.
I didn’t care that much, though, because normally I’d rather just use a local client (git directly or maybe magit in emacs).
the once-industry-leading status page no longer reports minor availability issues in an even vaguely timely manner;
Can’t deal with issue-tracking with a local client, though.
What does the author mean with “legacy”? I thought that meant “abandoned”. Github is nowhere near abandoned. People keep flocking to it and giving it more power.
If it becomes too shitty to use, my guess is that the majority will still stay because of inertia. Regardless of what alternatives exist, the majority stays with the popular.
What does the author mean with “legacy”? I thought that meant “abandoned”.
Legacy to me does not mean abandoned, but the previous version that is still needed. It does not tell you if its “supported”. Abandoned would be a software no longer in “supported” to me. But that does not say if its still needed today. So legacy and abandoned are similar, but not the same, only sometimes the same. Legacy software or hardware can be popular in usage too. In example old graphics cards like GTX 1070 are legacy and use legacy drivers. They are somewhat popular still. The official drivers from Nvidia still support this older graphics card, so they are not abandoned, only legacy.
This is what my definition of these words. I don’t think Github itself is legacy nor abandoned. I personally am just a very simple Git user and use Github through the
gitcommand and for some tasks through the website of Github. It’s fine for me and I don’t care if someone calls it legacy or abandoned. It’s not.When she says it’s starting to feel like legacy software, I think she means parts of it seem to be falling into disrepair. Some things that once worked consistently and easily, like using the browser’s built-in search, no longer do.
That isn’t what legacy means.
But you can still understand the gist of the article even if it used that word differently.
The author’s made at a new tech breaking an old feature. Seems more to me like a “I wish they kept things the same” than “I wish they changed some stuff around here”. Quite the opposite of legacy.
It being the main point of the article bug being used incorrectly in the title is just confusing. That’s comparable to somebody always mentioning “wolf” in an article, actually describing a hare and never saying what their definition of a wolf is.
I totally get what you’re saying, but wouldn’t you rather discuss the content of the article than argue about definitions?
Sure, IMO github has had a subpar interface forever. I’ve always liked Gitlab’s interface more. Github has felt behind Gitlab for a while and it feels like the major thing they have going for themselves are Github Actions and marketshare. The interface getting worse is no issue to me as I try not to use it anyway.
It also doesn’t seem comprehensible to me that the author prefers Github’s blame interface over every git GUI they’ve used. They don’t even say what it is about the interface they find nicer.
I really like GitHub’s high contrast themes. But yeah, that’s it. I recently moved my code to Codeberg. Have you tried it? I like GitLab too. That was my go to back when GitHub didn’t offer free private repos.
The meaning of words often varies with context.
Techical terms with specific meanings don’t vary significantly based on context, because consistency is important in technical usage.
The author is complaining about how guthub is being poorly modernized, which is the opposite of legacy software. If she means ‘something we choose use out of tradition’ that isn’t what legacy software means.
Techical terms with specific meanings don’t vary significantly based on context
Every lexicographer I know would challenge that notion. (And I’ve had more than a few experiences in technical fields that challenge it as well.)
People sometimes express themselves using words that might not fit the discussed situation directly (at least not in the typical way), but do fit closely-associated experiences they’ve had. They use them because those are the words that come to mind at the time.
We could pedantically gatekeep their use of language and insist that their views/experiences are invalid because we don’t like their choice of words…
…or we could try to understand them.
What a great point to make about language in situations that are not technical! Like how theory is used differently outside of scientific contexts, which is language naturally evolving.
But this is like someone trying to use the lay definition of theory, which is the equivalent of a hypothesis in acience, in a scientific context. A scientist saying “that is just a theory” to dismiss the theory of relativity in a scientific context would be rightfully corrected by their peers.
Using legacy software wrong is like using API to describe something other than an API.
You’ve made your opinion clear; restating it and slinging downvotes doesn’t help anyone. Good day.
Legacy means outdated. Not [necessarily] unusable or unstable or insecure or needs to be updated. But feels old or outdated. Conforming to older standards or workflows.
Wikipedia matches my understanding:
In computing, a legacy system is an old method, technology, computer system, or application program, “of, relating to, or being a previous or outdated computer system”, yet still in use.
Then I think the author also had a different understanding of the term, because he’s complaining about new functionality breaking an old feature. Introducing new code is quite the opposite of legacy.
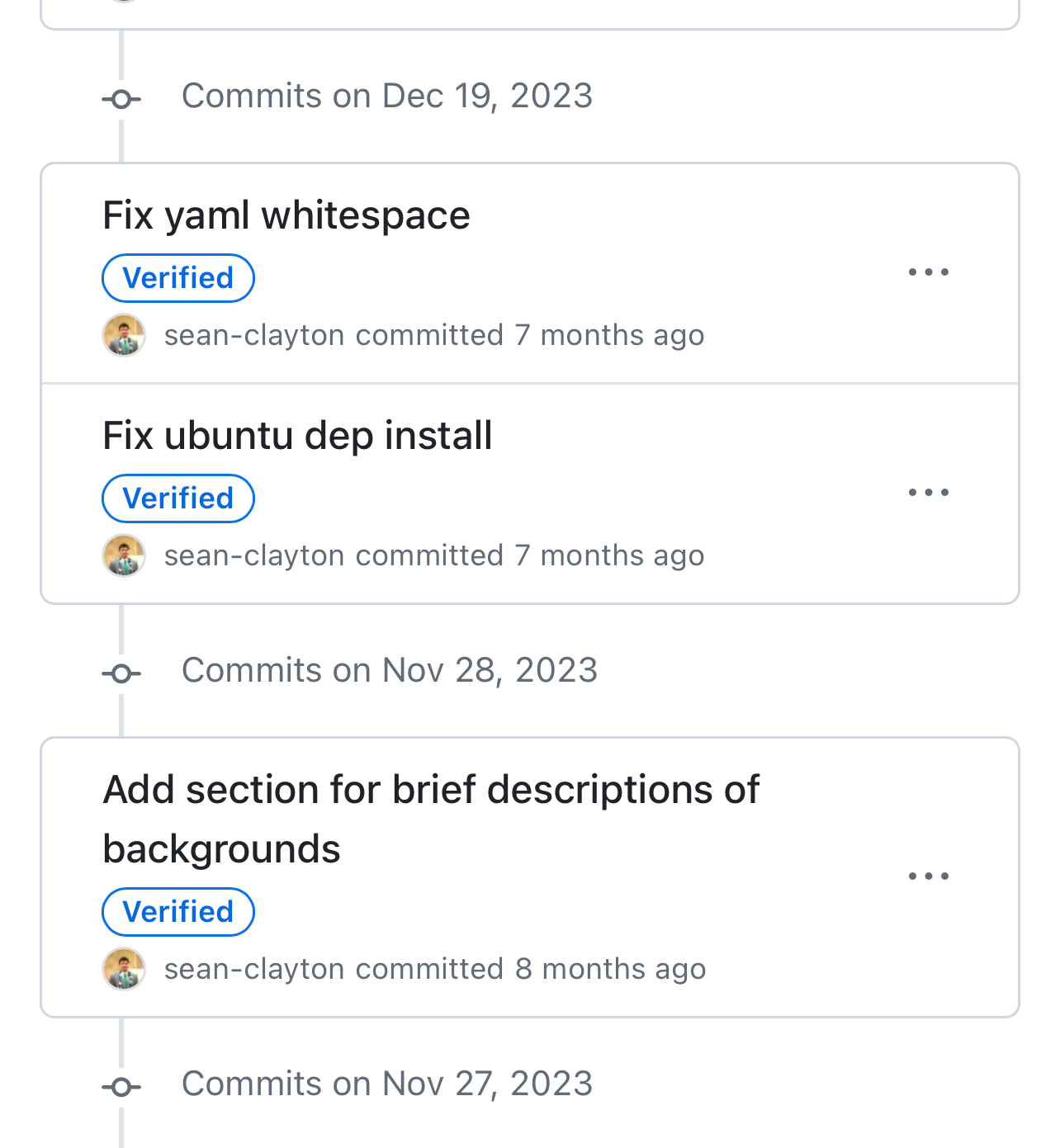
The fact that the dates in the commit log are relative is stupid as shit. I am looking for the commit on March 14th at 3pm, not “last year”
edit: I’m an idiot 😭
edit 2: I just noticed that GitHub’s git log does show exact dates, only as headings though, not on each commit.
Tell me what you found out!?
See my edit :P
Don’t be xkcd Denver coder, tell us how you fixed this shit right now
I don’t think I’ve ever paid attention at those “headings”, it looks just visual noise for me. But it looks like it should be the other way around, the headings should group commits time-related (7 months ago) and each commit should display its exact date.
Yeah I agree, I never noticed until I looked again right after I made my comment 😂
We need to know! Using GitHub at the moment and this is driving me fucking wild.
I’ve used several different forges over my career and github is the worst by far. The navigation is clunky, the search never searches the stuff you want to look at without menu hopping, the recent repos doesn’t include half the stuff you made a PR to recently, CI integration kinda sucks compared to gitlab or bitbucket.
Worse than Sourceforge? Savannah?
The company i was with was still using clearcase when those were popular. I’ve used github, gitlab, and bitbucket as git based software forges professionally. In fairness Github is way better than the clearcase process we used.
No, those are ancient. Worse than gitlab. And some of the newer ones
I don’t think this is an anti-React post, like the other commenters are implying.
This issue would occur when attempting to search any webpage with the web browser’s builtin search feature before the content has a chance to load in. This happens if the page requires JavaScript to load, which is the case with React apps.
Honestly I got no problem with GitHub and use it everyday on a large open-source code base and it works like a charm.
Edge does that shit too with JSON… It made me switch to Firefox, so good for me (other than that Firefox has a tendency to enshittify too, but in different ways).
Quit with this Firefox “enshittification” bs. It isn’t true. Be better.
https://www.spacebar.news/mozilla-firefox-privacy-preserving-attribution/
Wasn’t talking about that, but OK Boomer.
You’re about 30 years off, but nice try.
You absolutely were talking about that. Maybe not as your main point, but it was part of your statement.
I want to self host instead, but then there’s always the “what if a tornado hits my house and I lose my life’s work?” fear that keeps me using GitHub…
Edit: thanks for the suggestions, I’ll look into them!
Self host with backups set up?
Try Codeberg!
There is always sourcehut
Not sure if that’s for you, but I’ve moved my stuff to forgejo hosted on uberspace. Not your own server, but I find it hits the sweet spot between convenience and control.
More people need to give Gitlab a chance. It’s really come into its own and I agree that Github now feels like typical unfocused, bloated MS software.
I truly can’t. I have pet peeves with GitHub but overall it’s good and the UI is clear enough. I have to use gitlab for a few projects and it’s so damn confusing, with so many little annoying things I just can’t stand it.
Gitlab feels also a bit weird to me, though.
The git part is perfectly fine, but at my job we’re trying to get our cloud tool landscape to work with gitlab CI and it’s really a struggle.
Something as simple as packaging the same artifact in two different ways or running tests in docker images before pushing them is really hard. Gitlab seems to insist on having a single commit as its entire context and communication between stages (especially on different runners) is almost laughably limited.
Jenkins on the other hand has at least the option to have a shared workspace. Yes, this has its downsides, but at least I have the option. Gitlab forces you to use outside tools in very involved ways or follow exactly their own, highly opinionated approach.
GitLab just doesn’t compare in my view:
To begin with, you have three different major versions to work with:
- Self-Hosted open source
- SAAS open source
- Enterprise SAAS
Each of which have different features available and limitations, but all sharing the same documentation- A recipe for confusion if ever I saw one. Some of what’s documented only applies to you the enterprise SAAS as used by GitLab themselves and not available to customers.
Whilst theoretically, it should be possible to have a gitlab pipeline equivalent to GitHub actions, invariably these seem to metastasize In production to use
includesmaking them tens or hundreds of thousands of lines long. Yes, I’m speaking from production experience across multiple organisations. Things that you would think were obvious and straightforward, especially coming from GitHub actions, seen difficult or impossible, example:I wanted to set up a GitHub action for a little Golang app: on push to any branch run tests and make a release build available, retaining artefacts for a week. On merging to main, make a release build available with artefacts retained indefinitely. Took me a couple of hours when I’d never done this before but all more or less as one would expect. I tried to do the equivalent in gitlab free SAAS and I gave up after a day and a half- testing and building was okay but it seems that you’re expected to use a third party artefact store. Yes, you could make the case that this is outside of remit, although given that the major competitor or alternative supports this, that seems a strange position. In any case though, you would expect it to be clearly documented, it isn’t or at least wasn’t 6 months ago.
deleted by creator












{kind=link}